ამ სტატიაში ვისაუბრებთ შემდეგ თემებზე:
->lazy initialization
->Singleton
->double-checked locking
->volatile (JIT ში და ASM შიც)
Ok, lets start it!...
### lazy initialization ####
lazy initialization არის ტაქტიკა, როდესაც თქვენ აფერხებთ ობიექტის შექმნას. ამასთან ომპიტიზაციასაც ვაკეთებთ.
class ResourceManager{
private Resource resource;
public Resource getResource(){
if ( resource == null ){
resource = new Resource();
}
return resource;
}
}
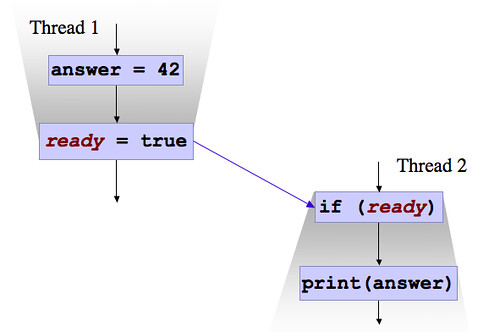
შევხედოთ სრდედების თვალით, რა შეიძლება მოხდეს. მოვიდა სრედი I , ნახა ობიექტი არის ნალი, და შექმნა ობიექტი. ამასთან, II სრედმაც ნახა რომ null არის და შექმნა... თუ გვინდა, რომ ორივე სრედს ერთიდაიგივე instance ქონდეს, მაშინ singleton დაგვჭირდება (ერთერთი GoF Design Pattern იდან).
### singleton Pattern ####
class Resource{
private static Resource instance;
public static Resource getInstance(){
if ( instance == null){
instance = new Resource();
}
return instance;
}
}
როდესაც აქ მულტი სრედინგით დავიწყებთ ყურებას synchronized დაგჭირდება... მაგრამ, როდესა ერთ სრედი გაეშვება პრობლემა lock-ისა დაგვხვდება.... ამ პრობლემის გადასაჭრელად Double-Checked Locking პატერნი გამოვიყენოთ...
### Double-Checked Locking ###
ამ შემთხვევაში, მეთოდები არ არიან დასინქრონიზირებულები (წინა შემთხვევაში გვქონდა და ლოქის პრობლემა გვქონდა),
არამედ ინსტანსის შექმნის კოდი ჩაჯდება სინქრონიზაციის ბლოკში.
class Resource{
private static Resource instance;
public static Resource getInstance(){
if ( instance == null ){
synchronized(Resource.class){
if ( instance == null ){
instance = new Resource();
}
}
}
return instance;
}
}
თუ ერთი სრედი შესული არის სინქრონიზაიის ბლოკში, სხვები დაელოდებიან სანამ ინიციალიზება არ მოხდება.
პრობლემა ისაა რომ ინიიალიზება და ობიექტის შექმნა სხვადასხვა ადგილასაა. ანუ , პრობლემა ისაა, რომ ერთი სრედი სანამ სინქრონიზაციის ბლოკშია, მეორე როდესაც შემოვა ( და ამასთან იმის გამო რომ instancce==null), ეს სრედი ეცდება შექმნას ობიექტი... ოოპს! გავიჭედეთ! stuck in the desert! - ფიქრის შედეგად აღმოვაჩენთ , რომ ის არ არის რაც ჩვენ გვიდნა. ნუ, თუ არ ვიფიქრეთ ვერც აღმოვაჩენთ.
(პ.ს ისე ამაზე ინფო დეტალურად Java Concurrency in Practice წიგნში შეგიძლიათ წაიკითხოთ, ეს არის ძალიან ძალიან მაგარი წიგნი, და ყველა პროგტამისტს უნდა ქონდეს წაკითხული. ამაზონზე თან სულ ახლახანს გაიაფდა).
აბა პრობლემას როგორ გადაჭრით? რამდენიმე გზა არსებობს. აი იმ წიგნში მე რომელიც გითხარით, იქ ნახავთ დაწვრილებით ისე ყველაფერს. უცბათ ერთერთ გზას შემოგთავაზებთ:
class Resource{
private static class ResourceHolder{
static final Resource instance = new Resource();
}
public static Resource getInstance(){
return ResourceHolder.instance;
}
}
მოდით გავაგრძელოთ და ეგრედ წოდებული volatile ზე გადავიდეთ და თან ამ თემასაც დავუკავშირებთ.
მოკლედ, იმისათვის რომ volatile ზე ვისაუბროთ, ჯერ ჯავას memory model უნდა ვიცოდეთ, თუ როგორ მუშაობს - ყველა სრედი, ჯავაში, გამოიყოფს თავის ცალკეულ ადგილს მემორიდან. ანუ თუ კვენ ერთ სტორიჯს გამოვუყობთ ყველაფერს ეშველება - გავიხარებთ ყველანი. ანუ ვიპოვეთ გზა რითიც Virtual Mahine-ს ვაიძულებთ რომ არ შექმნას ტემპორარი კოპოიოები ცვლადების. (მოკლედ, ბევრს აღარ გავაგრძელებ, სიღრმისეულია ეს თემა, და atomc variable ზე ბევრი რამეს დაწერა შეილება - სალაპარაკოს რა გამოლევს, დრო ვთქათ თორე...)
პატარა მგალით მოვიყვანოთ. წარმოიდგინეთ ორი სრედი, ერთში ცვლადს ენიჭება მნიშვნელობა, მეორეშ სრედში ამ ცვლადს ვკითხულობთ პირდაპირ. ეს შეილება მარტივად გამოვიყენოთ სრედის გაჩერებაშიც (რათქმაუნდა interruptი შეგიძლიათ), მხოლოდ loop დაგვჭირდება.
public void run(){
while(stop!=true){
// სრედი არ კვდება
}
}
ვიზუალურადაც ვაჩვენოთ. ორი სრედი. როდესაც ერთში შეიცვლება მნიშვნელობა, მეორე იგივე STORE დან იღებს. მოკლედ ASM ში როგორ არის იმას დაბლა დავწერ. ჯერ ეს საკმარისია.
ასეთი რამეც შეიძლება გავაკეთოთ (აქაც იგივე გავაკეთე, პროსტა, ობიექტის რასაც ვანიჭებთ volatile არის. სხვა არაფერი). ანუ დარწმუნებული ვართ რომ თუ ერთმა სრედმა მნიშვნელობა მიანიჭა ცვლადს, მეორე ცვლადში ეგრევე აისახება.
class Foo {
private volatile Helper helper = null;
public Helper getHelper() {
if (helper == null) {
synchronized(this) {
if (helper == null) {
helper = new Helper();
}
}
}
return helper;
}
ახლა JIT ში რახდება ის ვნახოთ. რაც არ უნდა იყს, ვერ გავექცევით, JIT ში ომპტიმიზაცია ასე მოხდება
while (test.loop == true) ;
// გადავა შემდეგ კოდში =>
if (test.loop) { while (true); }
ოკ, და რეალურად მთლიანი STORE შეინახება EAX რეგისტრში.
volatile მდე იქნებოდა:
00000068 test eax,eax
0000006a jne 00000068
//შემდეგ კი
00000064 cmp byte ptr [eax+4],0
00000068 jne 00000064
ყოველი სრედი, იგივე მემორიდან ამოიღებს ცვლადის მნიშვნელბოას (ptr [eax+4])
რა კითხვებიც გექნებად დაწერეთ, არ მოგერიდოთ! :-)